Engineering Leadership
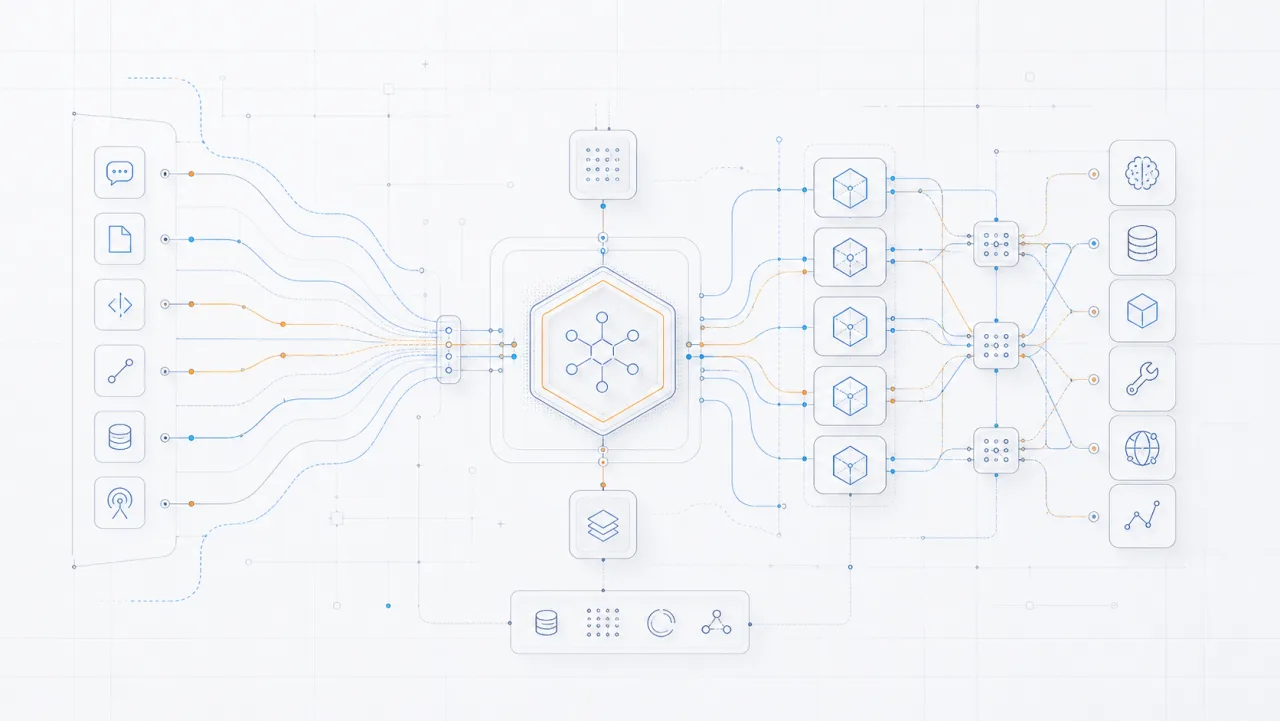
Lakehouse architecture overview (7 layers)
Seven-layer Lakehouse: Ingestion (Airbyte, Kafka), Processing (Spark, Flink, dbt), Storage Format (Iceberg, Delta), MinIO, Metadata, Trino, Consumption.
2026-03-171 min read
Design goals
- Unified data: Single source of truth for the organization
- Real-time analytics: Batch and streaming
- Scalability: Scale with business demand
- Cost efficiency: Open source stack
- Compliance: e.g. personal data regulations (applicable data protection regulations)
Seven-layer architecture
| Layer | Purpose | Technology | Pattern |
|---|---|---|---|
| 1. Ingestion | Collect from source systems | Airbyte, Kafka, Logstash | CDC, event streaming, batch |
| 2. Processing | Process, clean, transform | Spark, Flink, dbt | ETL/ELT, stream processing |
| 3. Storage Format | Storage format, schema evolution | Iceberg, Delta Lake, Parquet | ACID, time travel |
| 4. Storage | Physical object storage | MinIO (S3-compatible) | Partitioning, compression |
| 5. Metadata & Catalog | Lineage, governance | DataHub, Apache Atlas | Discovery, lineage, quality |
| 6. Query | SQL engine | Trino, DuckDB | Federated queries, caching |
| 7. Consumption | End-user consumption | Superset, FastAPI, MLflow | BI, API, ML serving |
Data flow
Source Systems → Ingestion → Processing → Storage Format → Object Storage → Metadata Catalog → Query Engine → Consumption apps.
Source system → Lakehouse mapping
| Source system (example) | Ingestion method | Target layer |
|---|---|---|
| CRM (PostgreSQL) | Airbyte CDC | Raw → Staging |
| Core Lending (SQL Server) | Batch ETL | Raw → Curated |
| Payment APIs | Kafka streaming | Raw → Analytics |
| Risk Engine | File-based ETL | Staging → Curated |
Data organization
Layers: raw/ (immutable) → staging/ → curated/ → analytics/
Naming: {environment}/{layer}/{domain}/{table_name}/
Example: prod/curated/customer/customer_master/, staging/raw/lending/loan_applications/